In the vast and ever-expanding world of Big Data, it’s easy to get lost in a sea of acronyms and technical jargon. But understanding one fundamental concept can dramatically impact the efficiency, speed, and cost of your data operations: data formats.
Think of data formats like different filing systems for a massive library. Some systems are great for quickly adding new books, others are optimized for finding specific information across many books, and some are just for easily sharing small collections. Choosing the right one isn’t just a technical detail; it’s a strategic decision.
Let’s dive into the three main categories of Big Data formats and when to use them.
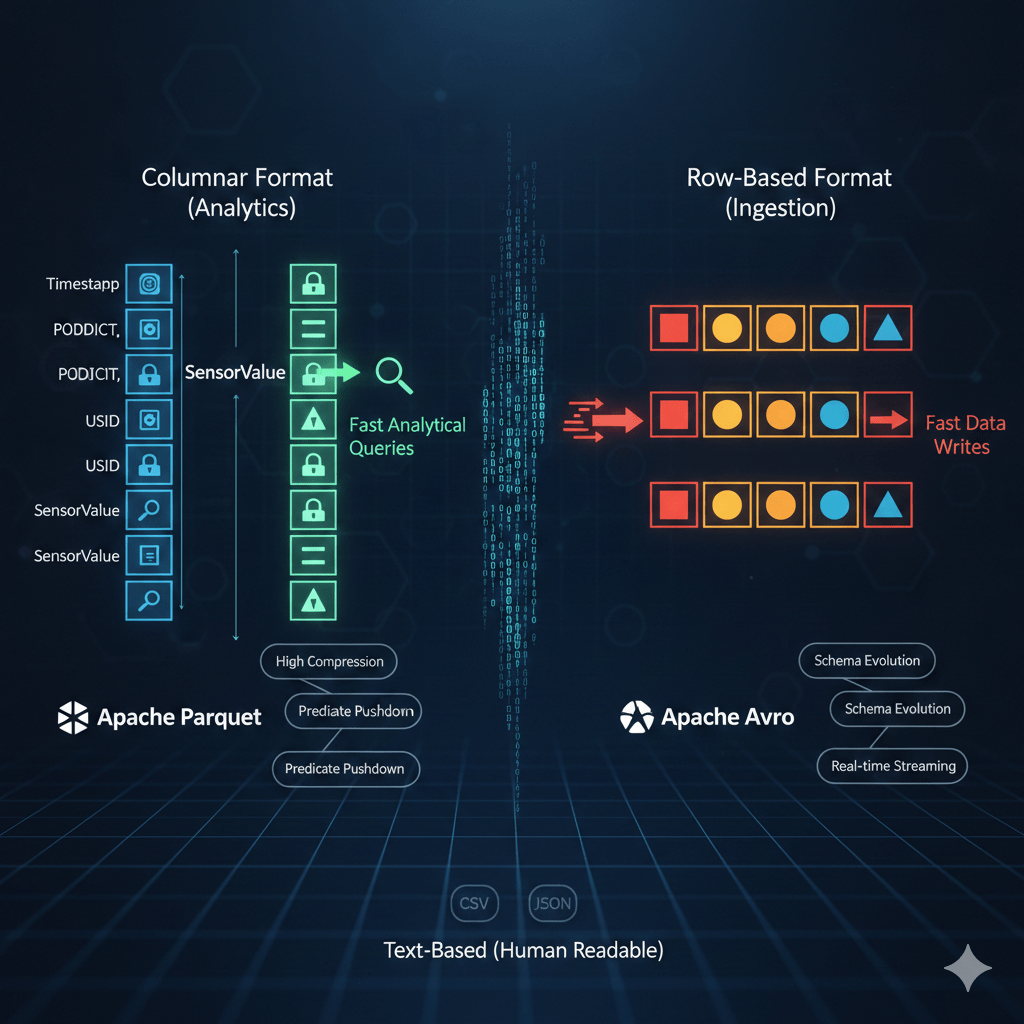
1. The Powerhouses of Analytics: Columnar Formats
Imagine you have a spreadsheet with millions of rows and hundreds of columns. If you only ever want to calculate the average of a single column (e.g., “Total Sales”), why should your computer have to read all the other columns like “Customer Name,” “Product ID,” and “Order Date” for every single row?
That’s the genius of columnar formats. Instead of storing data row-by-row, they store it column-by-column. This means when you query a specific column, the system only needs to read that particular column’s data, ignoring everything else. This leads to blazing fast analytical queries and incredible compression ratios.
- Apache Parquet: The undisputed champion for general-purpose big data analytics. If you’re using tools like Apache Spark, AWS Athena, or Google BigQuery, Parquet is your go-to. It offers superior compression and “predicate pushdown” – meaning filters are applied at the storage level, reducing the amount of data read significantly.
- Apache ORC (Optimized Row Columnar): While similar to Parquet, ORC is particularly optimized for the Hadoop/Hive ecosystem. It boasts excellent compression and plays very well with Hive’s advanced features, including supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions for updates and deletes.
When to use them: When your primary goal is to run complex analytical queries, generate reports, or power business intelligence dashboards on massive datasets.
2. The Speedy Writers: Row-Based Formats
Sometimes, speed isn’t about querying; it’s about getting new data into your system as quickly as possible. This is where row-based formats shine. They store data record by record, making it incredibly efficient to append new information.
- Apache Avro: A star player in the world of real-time data streaming and ETL (Extract, Transform, Load) pipelines. Avro is exceptional at handling “schema evolution.” This means if you decide to add a new field to your data or change an existing one, Avro can gracefully handle older data with the previous schema alongside newer data. It stores the schema (metadata) with the data, ensuring compatibility.
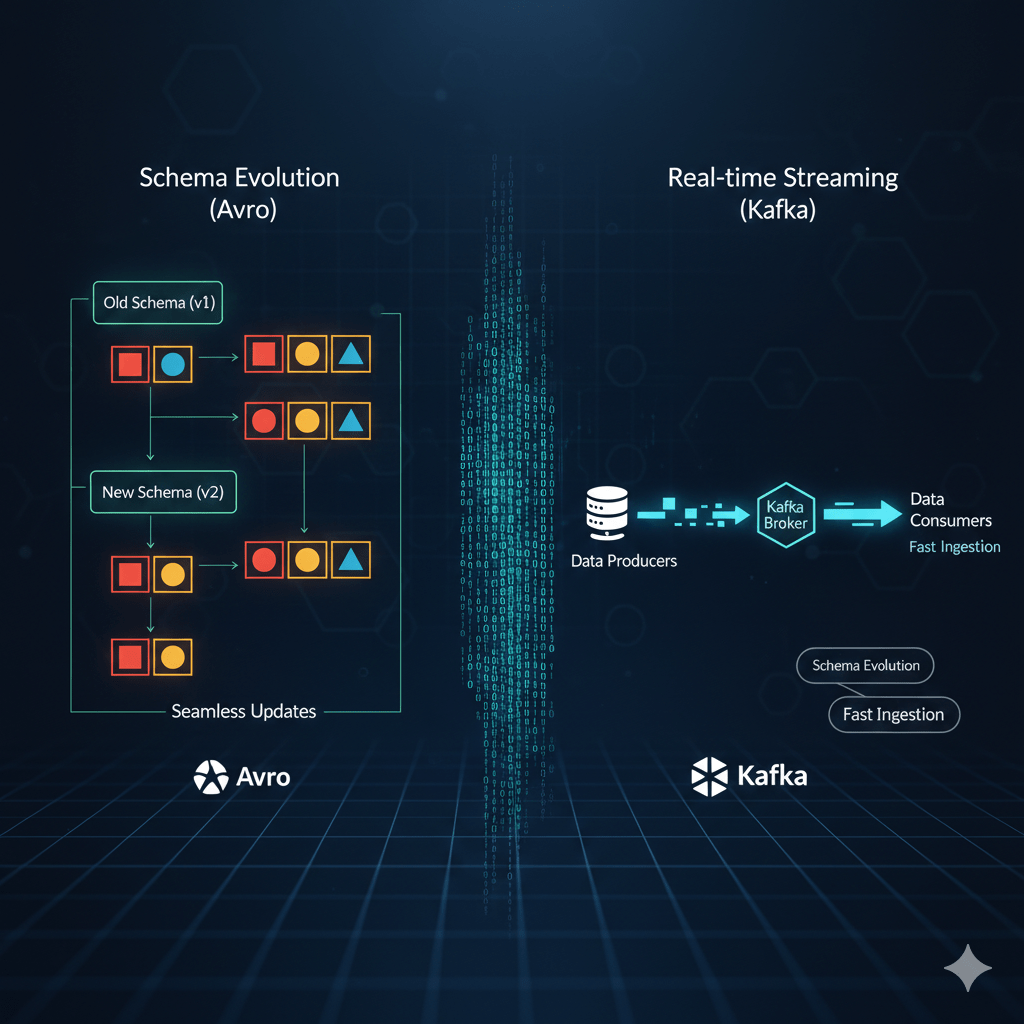
When to use it: For high-throughput data ingestion, streaming data platforms (like Apache Kafka), and scenarios where your data schema is likely to evolve over time.
3. The Human-Readable Basics: Text-Based Formats
While not designed for petabyte-scale processing, text-based formats are crucial for human readability, interoperability, and initial data landing.
- CSV (Comma-Separated Values): Simple, universal, and easily opened in any spreadsheet program or text editor. CSV files lack intrinsic metadata, meaning you need external knowledge of what each column represents.
- JSON (JavaScript Object Notation): A flexible format that supports nested data structures, making it great for complex, semi-structured information. However, its “verbose” nature (repeating field names for every record) can lead to larger file sizes compared to binary formats.

When to use them: For smaller datasets, data exchange between different systems, configuration files, or when you need to quickly inspect data manually.
Choosing Your Champion: A Quick Guide
| Scenario | Recommended Format(s) | Why? |
| Building a Data Lake for SQL Analytics & BI | Parquet | Unmatched query performance and compression for columnar analytics. |
| High-Throughput Data Ingestion & Streaming | Avro | Fast writes and excellent schema evolution capabilities. |
| Sharing Small Datasets with Non-Technical Users | CSV | Universal readability and simplicity. |
| Storing Semi-Structured Data (e.g., API responses) | JSON | Flexibility for nested data, but be mindful of size for large volumes. |
| Hadoop/Hive-Centric Environments | ORC | Optimized for the Hive ecosystem with strong compression and features. |
The Bottom Line
There’s no single “best” big data format. The optimal choice always depends on your specific use case, infrastructure, and performance requirements. By understanding the strengths and weaknesses of columnar, row-based, and text-based formats, you can make informed decisions that will lead to more efficient, cost-effective, and robust big data architectures.
What formats are you currently using, and what challenges have you faced? Share your experiences in the comments below!

Leave a comment