Over the years, I’ve found that the best way to learn a technology isn’t by reading documentation cover to cover; it’s by being challenged. This post is designed exactly for that.
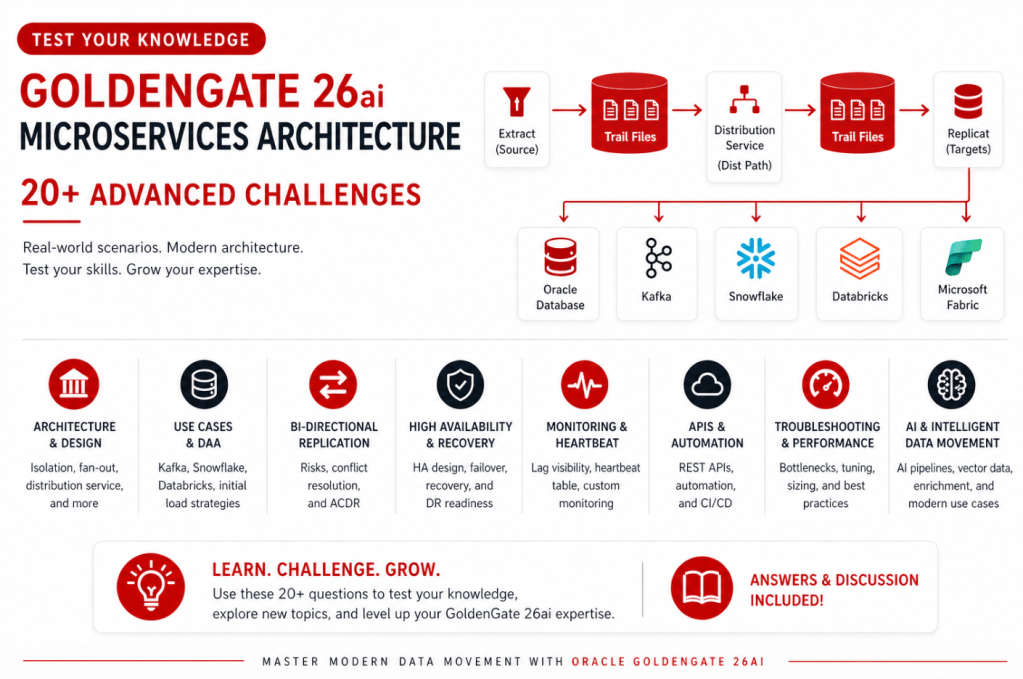
These are not beginner questions. They reflect real-world scenarios I’ve seen with users working with Oracle GoldenGate 26ai Microservices Architecture; from bi-directional replication and high availability to Data Streaming and modern data platforms like Kafka, Snowflake, and Databricks.
👉 The goal is simple:
- Test your knowledge
- Identify gaps
- Explore topics you may not have worked with yet
Take your time. Try to answer each question before scrolling to the answers.
The Challenge
Architecture & Design
1. How would you design a GoldenGate Microservices deployment where multiple teams require isolation, but infrastructure must be shared?
2. What are the architectural differences between Distribution Service and a Classic data pump, and how do those differences impact data transformation strategies?
3. How would you design a fan-out architecture where different downstream systems require different levels of data filtering or masking?
Use Cases & Modern Data Platforms (DAA)
4. How would you design a pipeline that delivers Oracle data simultaneously to Kafka and Snowflake?
5. What is your strategy for performing an initial load for a heterogeneous target (e.g., Databricks) while keeping systems in sync with minimal downtime?
Bi-Directional / Active-Active
6. What are the key risks in bi-directional replication, and how do you mitigate them in Microservices?
7. When would you rely on GoldenGate ACDR versus handling conflicts at the application level?
High Availability & Recovery
8. How would you design a highly available GoldenGate deployment in Kubernetes or cloud environments?
9. A Replicat abends and falls behind significantly—how do you recover without introducing inconsistencies?
10. What are the main challenges during a cross-region failover (DR), and how do you prepare for them?
Data Stream (26ai)
11. What is the GoldenGate Data Stream capability, and how does it differ from traditional trail-based replication?
12. When would you choose Data Stream over Kafka-based delivery using DAA?
Monitoring & Observability
13. How does the Heartbeat Table enable end-to-end lag monitoring, and what happens if it is not configured?
14. How would you design a custom monitoring solution using GoldenGate REST APIs?
APIs & Automation
15. How would you fully automate a replication pipeline using Microservices APIs?
16. What are the advantages of REST-based management compared to traditional AdminClient usage?
Troubleshooting
17. A Replicat is running but not applying transactions—what steps would you take to troubleshoot?
18. How do you distinguish between Extract-side and Replicat-side performance bottlenecks?
Performance & Sizing
19. How would you size GoldenGate for a high-throughput system (e.g., >1TB/hour of redo)?
20. What are the most effective techniques to improve Replicat performance?
AI & Intelligent Data Movement (26ai)
21. How can GoldenGate 26ai integrate with AI/ML pipelines, particularly when working with vector-based data and embedding generation?
22. What are the architectural considerations when replicating data into AI-driven platforms (e.g., vector databases, feature stores, or AI services)?
23. How would you design a pipeline where transactional data is enriched in real time using AI services during replication?
Answers & Discussion
(Don’t treat these as the only correct answers; real-world design always depends on context.)
1. Isolation in Shared Deployments
Use multiple deployments or enforce RBAC with Admin Service. Consider separating workloads logically while sharing infrastructure, depending on governance and security needs.
2. Distribution Service vs Data Pump
Distribution Service provides routing and lightweight filtering only; no transformations. Transformations must happen upstream (Extract/Replicat), which significantly impacts design decisions.
3. Fan-Out with Different Requirements
Use multiple distribution paths and/or duplicate mappings at Extract. In some cases, use tokens or upstream logic to differentiate data streams.
4. Kafka + Snowflake Delivery
Leverage DAA with separate Replicats per target. Decide whether to reuse trails or create dedicated pipelines depending on performance and isolation needs.
5. Initial Load Strategy
Use external bulk load (faster) + CDC synchronization via SCN alignment. GoldenGate initial load can be used but may not scale well for large datasets.
6. Bi-Directional Risks
Looping, conflicts, and latency. Mitigation includes proper key design, filtering, and potentially ACDR.
7. ACDR vs Application Logic
Use ACDR when conflicts are predictable and simple. Use application-level handling when business rules are complex.
8. HA in Kubernetes
Use persistent volumes for trails and checkpoints. Ensure stateless services can restart safely. Load balance service endpoints. I love this option.
9. Replicat Recovery
Leverage checkpoints. Validate consistency and consider reprocessing carefully to avoid duplicates.
10. DR Challenges
Endpoint changes, trail consistency, and network constraints. Predefine failover procedures and test them.
11. Data Stream
Provides event-driven streaming with structured output, enabling real-time integrations beyond traditional trail consumption.
12. Data Stream vs Kafka
Use Data Stream for lightweight, direct streaming. Use Kafka when ecosystem integration and decoupling are required.
13. Heartbeat Table
Enables end-to-end lag visibility. Without it, monitoring tools may not display accurate lag metrics. Now required for some WebUI metrics.
14. Custom Monitoring
Use REST APIs for Extract/Replicat status and metrics. Combine lag, checkpoint, and throughput data into dashboards. Use your imagination and what is best for your environment.
15. Automation via APIs
Automate creation, configuration, and lifecycle management using REST endpoints. Integrate into CI/CD pipelines.
16. REST vs AdminClient
REST enables automation, scalability, and integration with modern platforms. Senior resources specializes in the APIs, and AdminClient is for newbies. (My opinion).
17. Replicat Not Applying
Check checkpoints, lag, trail progression, and logs. Validate that data is being read and processed.
18. Bottleneck Identification
Compare Extract lag vs Replicat lag. Analyze throughput, CPU, I/O, and network behavior. First things first, make sure the bottleneck is not in the database or another downstream system.
19. Sizing
Balance CPU, I/O, and network. Use parallelism and ensure storage throughput supports trail activity.
20. Replicat Performance
Use Parallel Replicat, BATCHSQL, and optimize commit handling and dependency tracking.
21. AI + GoldenGate Integration
GoldenGate can feed AI pipelines by streaming data in real time. Vector data is typically handled similarly to LOBs, and transformations such as embedding generation may require external services or database functions.
22. AI Platform Considerations
Challenges include handling semi-structured data, schema evolution, and ensuring compatibility with vector or feature store formats. Latency and transformation location are key design decisions.
23. Real-Time AI Enrichment
Enrichment is typically done outside Distribution Service—either at Replicat or downstream. External AI services can be invoked, but this introduces latency and complexity that must be managed.
Final Thought
If you were able to confidently answer most of these, you’re operating at an advanced level.
If not—that’s the point.
GoldenGate, especially in its Microservices form, is no longer just replication. It’s a data movement platform, and mastering it requires thinking across architecture, streaming, APIs, and modern data ecosystems.
Drop me a note if you have any questions or need more information on any of those topics.

Leave a comment