Introduction
One of the most common challenges when setting up GoldenGate replication is the initial load, getting a consistent copy of the source data into the target database before starting change replication. The traditional approach is serial: extract all tables one by one, apply them, then start the change replicat. For small schemas this is fine. For schemas with hundreds of tables and millions of rows, it can take hours.
In Oracle-to-Oracle environments, initial data loads are typically handled using highly optimized native tools such as RMAN, Data Pump, or Data Guard. These approaches are efficient, proven, and purpose-built for Oracle workloads.
However, the landscape changes when working in heterogeneous environments. When the target system is Kafka, Snowflake, Databricks, or another modern data platform, those native options are no longer applicable. In these cases, GoldenGate native process often becomes the primary mechanism for both initial load.
The challenge is that traditional GoldenGate initial load approaches are largely serialized and can take considerable time when dealing with large datasets. This creates an opportunity to rethink how we approach initial load in these architectures.
In this session, we explore a pattern that leverages GoldenGate Microservices and its REST APIs to introduce parallelism and automation, significantly improving throughput and overall load times.
This post walks through initial_load_parallel.sh – a shell script that automates the entire initial load process using the GoldenGate 23.26 Microservices REST API, with a rolling queue of parallel extract pipelines, FK-aware delivery ordering, and SCN-precise startup of the change replicat to eliminate duplicate-key errors.
Everything here runs against real GoldenGate 23.26 Microservices and Oracle AI Database 26ai containers in a Docker lab. All API patterns were discovered by live testing against the actual GG REST API.
This walkthrough and script were developed and tested in a personal laptop environment with specific configurations and environment variables. As a result, they may not run successfully without adjustments in a different setup. If you copy and paste the process as-is, it will likely require some modifications to align with your environment.
The goal here is not to provide a plug-and-play script, but to educate and enable. This approach is used to demonstrate what’s possible with GoldenGate Microservices and its REST APIs. With some time invested in understanding and automating these APIs, you can adapt this pattern to your own environment and build a solution tailored to your specific requirements.
Environment
The lab runs in Docker Compose with the following containers:
| Container | Role | GG Admin Server |
|---|---|---|
oggWEST | Source GoldenGate hub | https://localhost:9090 |
oggEAST | Target GoldenGate hub | https://localhost:8080 |
dbWEST | Source Oracle DB (FREEPDB1) | — |
dbEAST | Target Oracle DB (FREEPDB1) | — |
The schema being loaded is Oracle’s sample HR schema – 7 tables with two levels of FK dependencies.
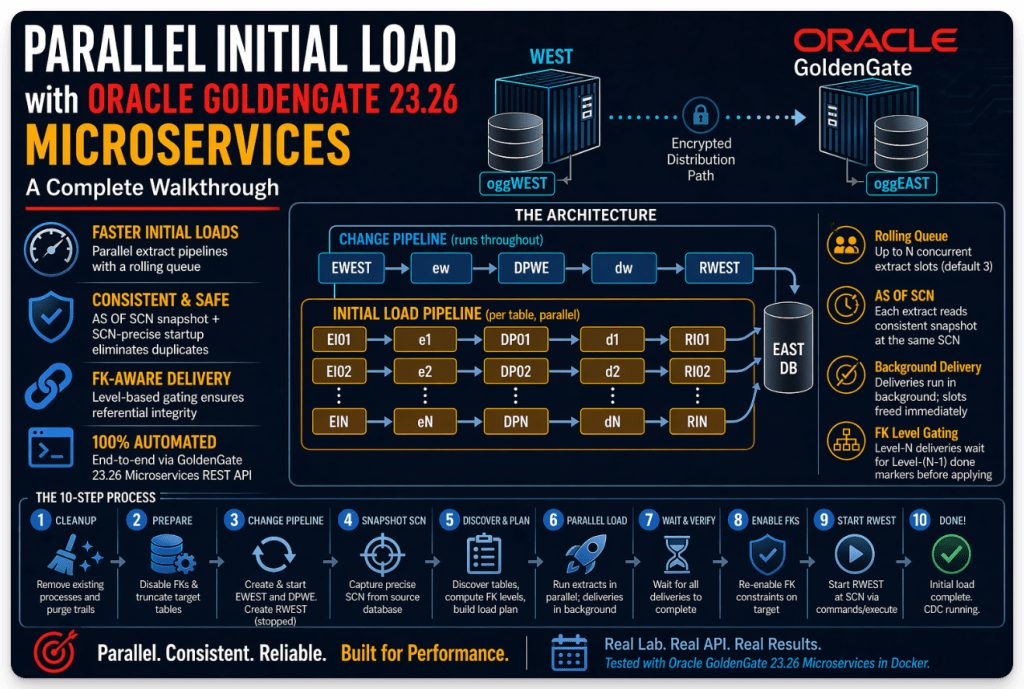
The Architecture
The script runs two types of pipelines in parallel: a single pipeline that continuously captures and delivers delta changes, and multiple initial load pipelines, one per table in the schema, all executing concurrently.
CHANGE pipeline (CDC - runs throughout): EWEST → trail ew → DPWE → trail dw → RWEST → EAST DBINITIAL LOAD pipeline (per table, parallel): EI<N> → trail e<N> → DP<N> → trail d<N> → RI<N> → EAST DB
The change pipeline starts first and accumulates all CDC changes while the initial load runs. The change replicat (RWEST) is created stopped and started at the end, positioned exactly at the snapshot SCN, so no CDC changes predating the initial load are replayed.
The Parallelism Model
The script uses a global rolling queue with a fixed concurrency of extract slots (default: 3).
EXTRACT PHASE (controlled - max N concurrent): Start N extract pipelines (EI+DP per table). Each extract reads one table AS OF SCN and self-stops. The instant any extract self-stops → slot freed → next table starts immediately.DELIVERY PHASE (background - no slot consumed): The instant an extract slot completes, its delivery launches in background: wait DP<N> lag=0 → create RI<N> → wait stable → stop RI<N> → write done marker. Deliveries run concurrently with all ongoing extracts.FK ORDERING (done-file gate): Level-N deliveries wait for Level-(N-1) done markers before starting RI<N>. Extracts are NOT gated - they run freely across all FK levels.
Example with HR (7 tables, 2 FK levels, 3 slots):
Start : EI01(COUNTRIES) + EI02(DEPARTMENTS) + EI03(EMPLOYEES)Slot 1 : COUNTRIES done → delivery01 background, EI04(JOBS) starts immediatelySlot 2 : DEPARTMENTS done → delivery02 background, EI05(LOCATIONS) starts immediatelySlot 3 : EMPLOYEES done → delivery03 background, EI06(REGIONS) starts immediatelySlot 4 : JOBS done → delivery04 background, EI07(JOB_HISTORY) starts immediatelySlot 5 : LOCATIONS done → delivery05 backgroundSlot 6 : REGIONS done → delivery06 backgroundSlot 7 : JOB_HISTORY done → delivery07 background (gates on level-0 done markers)End : wait all 7 deliveries → re-enable FKs → start RWEST at SCN
Process Naming
GoldenGate enforces an 8-character process name limit and a 2-character trail prefix limit. Each slot gets its own isolated pipeline:
| Process | Pattern | Trail |
|---|---|---|
| Extract | EI01..EI09 | e1..e9 on WEST |
| Dist Path | DP01..DP09 | forwards e<N> → d<N> |
| Replicat | RI01..RI09 | d1..d9 on EAST |
Prerequisites
- Oracle GoldenGate 23.26 Microservices running in Docker
- Source and target Oracle databases accessible from the containers
oggadmincredential alias configured in both GG hubsoggnetnetwork credential for WEST→EAST distribution path authentication- Checkpoint table
oggadmin.checkpointsexists on EAST jqinstalled on the host running the script- Bash 3.2+ (macOS compatible — no associative arrays or
wait -nused)
Configuration
At the top of the script, set these variables to match your environment:
INIT_PARALLELISM=${1:-3} # max concurrent extract slots (default 3, pass as arg)INIT_SCHEMA="HR" # schema to loadTRAIL_INIT_SIZE_MB=250 # max size of each initial load trail filePOLL_INTERVAL=15 # seconds between status checksPOLL_TIMEOUT=1800 # max wait per phase (30 min - raise for very large tables)
Environment variables (from .env):
OGG_ADMIN_PWD=... # oggadmin passwordDOCKER_OGG_EAST_IP=... # EAST GG container IP (for dist path target URI)DOCKER_DB_WEST_IP=... # WEST DB container IPDOCKER_DB_EAST_IP=... # EAST DB container IP
Step-by-Step Walkthrough
CLEANUP
Before creating anything, the script tears down any existing change pipeline and all leftover initial load processes from a previous run. This makes the script safe to re-run at any point.
# Reverse dependency order: Replicat → Dist Path → Extract stop_and_delete "replicats" "RWEST" ... stop_and_delete "sources" "DPWE" ... stop_and_delete "extracts" "EWEST" ...# Scan GG API for any leftover RI*, DP*, EI* processes cleanup_parallel_processes# Purge all trail files on both containers delete_trail_files "oggWEST" "ew" "e1".."e9" delete_trail_files "oggEAST" "dw" "d1".."d9"
The stop_and_delete function handles all status cases cleanly:
- NOT_FOUND → skip
- ABENDED → skip stop command, go straight to delete
- RUNNING → stop, poll until stopped, then delete
- STOPPED → delete immediately
- After DELETE, poll for 404 — GG deletes processes asynchronously
Step 3 — Disable FK Constraints + Truncate Target Tables
Before loading, all FK constraints on EAST must be disabled and all tables truncated. This runs as sysdba because oggadmin does not have ALTER ANY TABLE or TRUNCATE ANY TABLE privileges.
run_sql_as_sysdba "dbEAST" "FREEPDB1" "BEGIN FOR c IN (SELECT constraint_name, table_name FROM all_constraints WHERE owner = UPPER('HR') AND constraint_type = 'R' AND status = 'ENABLED') LOOP BEGIN EXECUTE IMMEDIATE 'ALTER TABLE HR.' || c.table_name || ' DISABLE CONSTRAINT ' || c.constraint_name; EXCEPTION WHEN OTHERS THEN IF SQLCODE = -26990 THEN NULL; ELSE RAISE; END IF; END; END LOOP;END;/..."
Important: ORA-26990 occurs on tables where GoldenGate has enabled allColumns supplemental logging (making them CDC tombstone tables). Oracle blocks ALTER TABLE constraint operations on these tables. The EXCEPTION WHEN SQLCODE = -26990 silently skips them — they can still be truncated normally.
The truncation loop handles FK ordering automatically by retrying deferred tables:
-- Truncate with retry loop for FK-ordered dependenciesWHILE v_pending.COUNT > 0 AND v_pass < 20 LOOP FOR i IN 1 .. v_pending.COUNT LOOP BEGIN EXECUTE IMMEDIATE 'TRUNCATE TABLE ' || v_pending(i); -- If successful, remove table from pending list v_pending.DELETE(i); EXCEPTION WHEN OTHERS THEN -- ORA-02266: cannot truncate a table referenced by enabled foreign keys IF SQLCODE = -2266 THEN NULL; -- defer to next pass ELSE RAISE; END IF; END; END LOOP; v_pass := v_pass + 1;END LOOP;
Step 5 — Create Change Extract (EWEST)
The integrated extract registers with Oracle DB logmining and captures all DML/DDL from the redo logs. It starts immediately and writes to trail ew.
api_call "POST" "https://localhost:9090/services/v2/extracts/EWEST" '{ "source": "tranlogs", "credentials": {"alias": "WEST"}, "registration": "default", "begin": "now", "status": "running", "config": [ "EXTRACT EWEST", "ENCRYPTTRAIL AES256", "EXTTRAIL ew", "USERIDALIAS WEST DOMAIN OracleGoldenGate", "TRANLOGOPTIONS EXCLUDETAG 00", "DDL INCLUDE MAPPED", "TABLE HR.*;" ]}'
Key: "source": "tranlogs" registers EWEST with the DB logmining server. Only one integrated extract can register per PDB — but this does not conflict with the initial load extracts created later, which use "source": "tables" (direct table read, no registration).
Step 5b — Copy Wallet + Create Change Dist Path (DPWE)
The distribution path forwards trail ew from WEST to EAST as trail dw. It uses the encryption wallet (copied from WEST to EAST first) and the oggnet network credential.
docker cp oggWEST:/u02/Deployment/var/lib/wallet/cwallet.sso .docker cp ./cwallet.sso oggEAST:/u02/Deployment/var/lib/wallet/cwallet.ssodocker exec -u 0 oggEAST chown 1001:root /u02/Deployment/var/lib/wallet/cwallet.sso
api_call "POST" "https://localhost:9090/services/v2/sources/DPWE" '{ "source": {"uri": "trail://localhost/services/WEST/distsrvr/v2/sources?trail=ew"}, "target": { "uri": "ws://<EAST_IP>:9014/services/v2/targets?trail=dw", "authenticationMethod": {"domain": "Network", "alias": "oggnet"} }, "begin": {"sequence": 0, "offset": 0}, "status": "running"}'
DPWE starts immediately — CDC changes begin accumulating on EAST as trail dw from this moment on.
Step 6 — Create Change Replicat (RWEST) — Stopped
RWEST is created without "status": "running" — it stays stopped. We don’t know the snapshot SCN yet, so we cannot position it correctly. It will be started at Step 10.
api_call "POST" "https://localhost:8080/services/v2/replicats/RWEST" '{ "mode": {"parallel": true, "type": "nonintegrated"}, "source": {"name": "dw"}, "checkpoint": {"table": "oggadmin.checkpoints"}, "config": [ "REPLICAT RWEST", "USERIDALIAS EAST DOMAIN OracleGoldenGate", "DDL INCLUDE MAPPED", "MAP hr.*, TARGET hr.*;" ]}'
Step 7 — Capture Snapshot SCN
This is the critical synchronization point between the initial load and the change pipeline.
SCN=$(docker exec -u oracle -i dbWEST bash -s <<BASHEOFsqlplus -s "oggadmin/...@//localhost:1521/freepdb1" <<SQLEOFSELECT NVL( (SELECT TO_CHAR(MIN(T.START_SCN)) FROM gv$transaction T INNER JOIN gv$session S ON S.SADDR = T.SES_ADDR WHERE T.STATUS = 'ACTIVE'), (SELECT TO_CHAR(current_scn) FROM v$database)) FROM dual;SQLEOFBASHEOF)
The query uses NVL to prefer the oldest active transaction’s start SCN over current_scn. This ensures that any in-flight transactions at snapshot time are fully captured by the initial load; using current_scn alone could miss rows from transactions that started before this point but haven’t committed yet.
Step 8 — Table Discovery, FK Ordering, and the Rolling Queue
This is the heart of the script. It runs in three phases:
Phase 1: Discover Tables
SELECT table_name FROM all_tablesWHERE owner = UPPER('HR')AND table_name NOT LIKE 'DT$_%' ESCAPE '\'ORDER BY table_name;
Phase 2: Compute FK Dependency Levels (Bellman-Ford)
FK relationships are queried from all_constraints:
SELECT TRIM(p.table_name) || ' ' || TRIM(c.table_name)FROM all_constraints cJOIN all_constraints p ON c.r_constraint_name = p.constraint_nameWHERE c.constraint_type = 'R'AND c.table_name != p.table_name;
Each FK edge (parent → child) means the child must be loaded after the parent. The compute_load_levels function uses Bellman-Ford relaxation to assign a numeric level to every table:
Dependency Level Calculation----------------------------1. Initialize all tables at Level 0.2. For each foreign key edge: child.level = max(child.level, parent.level + 1)3. Repeat step 2 until no table levels change.4. The calculation converges in at most N-1 iterations, where N is the number of tables.
For the HR schema this produces:
Level 0: COUNTRIES, JOBS, REGIONSLevel 1: DEPARTMENTS, EMPLOYEES, LOCATIONSLevel 2: JOB_HISTORY
The load plan is printed before execution:
Dependency Levels-----------------Level 0: COUNTRIES DEPARTMENTS EMPLOYEES JOBS LOCATIONS REGIONSLevel 1: JOB_HISTORYQueue Order-----------COUNTRIESDEPARTMENTSEMPLOYEESJOBSLOCATIONSREGIONSJOB_HISTORYExecution Model---------------- Extracts run with a maximum concurrency of 3.- Deliveries run in the background.- Level-N deliveries wait for Level-(N-1) done markers before starting RINIT.
Phase 3: The Rolling Queue (run_all_tables)
run_all_tables() { # Fill initial N extract slots while [[ $t_idx -lt $n && ${#ext_pids[@]} -lt $INIT_PARALLELISM ]]; do run_extract_slot "$table" "$slot" "$SCN" & ext_pids+=("$!") done # Rolling queue: poll for completions every 10 seconds while [[ ${#ext_pids[@]} -gt 0 ]]; do sleep 10 for each active extract PID: if still running → keep in active list if done: launch run_delivery_slot in background if more tables remain → start next extract immediately rebuild active list from survivors done # Wait for all background deliveries for each delivery PID: wait $pid || exit 1}
The Extract Phase –run_extract_slot
Each extract slot runs as a background subprocess and holds its slot until EINIT self-stops.
run_extract_slot() { local table=$1 local slot=$2 local scn=$3 # 1. Create EI<slot> # Source: tables; reads one table AS OF SCN api_call "POST" ".../extracts/EI0$slot" "{ \"source\": \"tables\", \"status\": \"running\", \"config\": [ \"EXTRACT EI0$slot\", \"EXTFILE e$slot MEGABYTES 250 PURGE\", \"TABLE HR.$table; SQLPREDICATE \\\"AS OF SCN $scn\\\";\" ] }" # 2. Create DP<slot> immediately # Streams trail e<slot> → d<slot> while EINIT writes api_call "POST" ".../sources/DP0$slot" "{ \"source\": { \"uri\": \"trail://.../sources?trail=e$slot\" }, \"target\": { \"uri\": \"ws://<EAST>:9014/...?trail=d$slot\" }, \"status\": \"running\" }" # 3. Wait for EI<slot> to self-stop # Function exits and slot is freed while not stopped; do sleep "$POLL_INTERVAL" done}
Why EXTFILE not EXTTRAIL? EXTTRAIL rejects the MEGABYTES parameter in source:tables mode. EXTFILE accepts it and writes a fixed-size file with PURGE to clean up after the dist path has forwarded it.
Why start DPEI immediately? GoldenGate trail files are written sequentially. DPEI can stream each file to EAST as EINIT writes it, so by the time EINIT self-stops, most of the data is already on EAST. For large tables, this reduces delivery lag from minutes to near zero.
AS OF SCN gives each extract a consistent snapshot of the table at the exact same point in time, regardless of when that extract slot actually runs. Tables loaded in slot 7 see the same data state as tables loaded in slot 1.
The Delivery Phase – run_delivery_slot
Each delivery runs entirely in the background. No extract slot is consumed.
run_delivery_slot() { local table=$1 local slot=$2 shift 2 # Parent tables that must complete before RINIT starts local wait_tables=("$@") # [Gate] Wait for parent-level done markers if [[ ${#wait_tables[@]} -gt 0 ]]; then until all "$WAVE_SYNC_DIR/<parent>.done" files exist; do sleep "$POLL_INTERVAL" done fi # 4. Wait for DP<slot> lag = 0 # Ensures all trail data has been forwarded to EAST until lag == 0; do sleep "$POLL_INTERVAL" done # 5. Create RI<slot> # Non-integrated Replicat reading trail d<slot> api_call "POST" ".../replicats/RI0$slot" "{ \"mode\": { \"parallel\": false, \"type\": \"nonintegrated\" }, \"source\": { \"name\": \"d$slot\" }, \"config\": [ \"REPLICAT RI0$slot\", \"MAP HR.$table, TARGET HR.$table;\" ], \"status\": \"running\" }" # 6. Wait for RI<slot> to stabilize at end of trail max_seq = last d<slot> file on oggEAST filesystem until cur_seq >= max_seq AND stable across 2 polls; do sleep "$POLL_INTERVAL" done # 7. Stop RI<slot> api_call "POST" ".../replicats/RI0$slot/command" '{ "command": "STOP" }' # Done marker - unblocks child-level deliveries echo "done" > "$WAVE_SYNC_DIR/$table.done"}
Why nonintegrated Replicat for the initial load?
The parallel script uses nonintegrated per-table Replicats. Each RI Replicat maps exactly one table from its assigned trail, which keeps the apply scope simple and avoids cross-table ordering concerns inside the Replicat. Cross-table dependencies are handled externally through FK dependency levels and done markers.
Nonintegrated Replicat is also simpler for this initial-load pattern and avoids relying on integrated Replicat behavior for short-lived, per-table apply tasks. The RI Replicat is still polled and stopped explicitly once its assigned trail is exhausted; it should not be assumed to self-stop automatically at end of trail.
FK gate mechanism: Done markers are plain files in /tmp/gg_wavedone_$$. A Level-1 delivery polls for the existence of all Level-0 <table>.done files before creating its RI. No database coordination required.
Step 9c – Re-enable FK Constraints
Once all deliveries have confirmed completion, FK constraints are re-enabled on EAST:
run_sql_as_sysdba "dbEAST" "FREEPDB1" 'BEGIN FOR c IN ( SELECT constraint_name, table_name FROM all_constraints WHERE owner = UPPER(''HR'') AND constraint_type = ''R'' AND status = ''DISABLED'' ) LOOP BEGIN EXECUTE IMMEDIATE ''ALTER TABLE HR.'' || c.table_name || '' ENABLE CONSTRAINT '' || c.constraint_name; EXCEPTION WHEN OTHERS THEN IF SQLCODE = -26990 THEN NULL; ELSE RAISE; END IF; END; END LOOP;END;/'
Step 10 – Start RWEST at the Snapshot SCN
This is the most critical step. RWEST has been accumulating CDC changes in trail dw since Step 5b. If we start it from the beginning of the trail, it will replay changes that were captured before the snapshot SCN, causing ORA-00001 duplicate-key errors because those rows are already in EAST from the initial load.
The solution is the POST /services/v2/commands/execute endpoint, which starts a replicat positioned AT a specific SCN:
api_call "POST" "https://localhost:8080/services/v2/commands/execute" '{ "$schema": "ogg:command", "name": "start", "processType": "replicat", "processName": "RWEST", "at": $SCN, "filterDuplicates": true}'
Parameters:
"at": <integer>— positions the trail reader AT this SCN (inclusive). Must be a bare integer, not a string."filterDuplicates": true— adds extra protection at the SCN boundary in case of edge cases.
Confirmed response from GG 23.26:
{ "messages": [ { "code": "OGG-00975", "title": "Replicat group RWEST starting." }, { "code": "OGG-15445", "title": "Replicat group RWEST started." } ]}
The script then polls until RWEST reaches RUNNING status.
Running the Script
cd /path/to/compose26aiGG# Default parallelism (3 concurrent extract slots)./initial_load_parallel.sh# Custom parallelism./initial_load_parallel.sh 5
Expected output (excerpt):
════════════════════════════════════════════════════════════CLEANUP: Removing existing pipeline and parallel initial load processes════════════════════════════════════════════════════════════--- Change pipeline --- Stopping RWEST (current: running)... ✔ RWEST status: running ✔ RWEST status: stopped Deleting RWEST... ✔ RWEST deleted. Stopping DPWE (current: running)... ✔ DPWE status: stopped Deleting DPWE... ✔ DPWE deleted. Stopping EWEST (current: running)... ✔ EWEST status: running ✔ EWEST status: running ✔ EWEST status: running ✔ EWEST status: stopped Deleting EWEST... ✔ EWEST deleted.--- Parallel initial load process cleanup --- Scanning for leftover RI* processes on EAST... Scanning for leftover DP* processes on WEST... Scanning for leftover EI* processes on WEST...--- Trail file cleanup --- Deleting 4 trail file(s) for 'ew' in oggWEST... ✔ Trail 'ew' files deleted from oggWEST. ⚠ No trail files for 'e1' in oggWEST — skipping. ⚠ No trail files for 'e2' in oggWEST — skipping. ⚠ No trail files for 'e3' in oggWEST — skipping. ⚠ No trail files for 'e4' in oggWEST — skipping. ⚠ No trail files for 'e5' in oggWEST — skipping. ⚠ No trail files for 'e6' in oggWEST — skipping. ⚠ No trail files for 'e7' in oggWEST — skipping. ⚠ No trail files for 'e8' in oggWEST — skipping. ⚠ No trail files for 'e9' in oggWEST — skipping. Deleting 40 trail file(s) for 'dw' in oggEAST... ✔ Trail 'dw' files deleted from oggEAST. ⚠ No trail files for 'd1' in oggEAST — skipping. ⚠ No trail files for 'd2' in oggEAST — skipping. ⚠ No trail files for 'd3' in oggEAST — skipping. ⚠ No trail files for 'd4' in oggEAST — skipping. ⚠ No trail files for 'd5' in oggEAST — skipping. ⚠ No trail files for 'd6' in oggEAST — skipping. ⚠ No trail files for 'd7' in oggEAST — skipping. ⚠ No trail files for 'd8' in oggEAST — skipping. ⚠ No trail files for 'd9' in oggEAST — skipping.════════════════════════════════════════════════════════════STEP 3: Disable FK constraints + truncate HR tables on TARGET (EAST) DB════════════════════════════════════════════════════════════ ✔ FK constraints disabled and all HR tables truncated on EAST DB.════════════════════════════════════════════════════════════STEP 5: Create change Extract (EWEST) on WEST GG════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════STEP 6: Create change Replicat (RWEST) on EAST GG — stopped════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════ STEP 7: Capture SCN from source (WEST) DB════════════════════════════════════════════════════════════ ✔ Captured SCN: 6644154════════════════════════════════════════════════════════════ STEP 8: Discover tables, compute FK load order, run parallel initial load════════════════════════════════════════════════════════════ ✔ Found 7 table(s) in HR. ✔ Querying FK dependency graph from source DB... ✔ FK-aware load plan: 7 table(s), 44 level(s), 3 concurrent extract slot(s): Level 0: JOBS REGIONS Level 1: COUNTRIES Level 2: LOCATIONS Queue order: COUNTRIES DEPARTMENTS EMPLOYEES JOBS LOCATIONS REGIONS JOB_HISTORY Extracts roll at 3 concurrent. Deliveries run in background. ✔ Slot 1 | Level 0 | Extract: HR.COUNTRIES ✔ Slot 2 | Level 0 | Extract: HR.DEPARTMENTS ✔ Slot 3 | Level 0 | Extract: HR.EMPLOYEES ✔ [Slot 1 | COUNTRIES] EI01 done - trail e1 written. Slot free. ✔ Slot 4 | Level 0 | Extract: HR.JOBS ✔ [Slot 1 | COUNTRIES] DELIVERY -- DP01 lag wait -> RI01 ... ...✔ [Slot 7 | JOB_HISTORY] DONE. HR.JOB_HISTORY fully loaded.════════════════════════════════════════════════════════════STEP 9: Re-enable FK constraints on TARGET (EAST) DB════════════════════════════════════════════════════════════ ✔ FK constraints re-enabled on EAST DB.════════════════════════════════════════════════════════════ STEP 10: Start change Replicat (RWEST) at SCN 6644154════════════════════════════════════════════════════════════ ✔ Starting RWEST at SCN 6644154 via commands/execute... ✔ RWEST status: running ✔ RWEST is RUNNING from SCN 6644154.════════════════════════════════════════════════════════════ ✔ Parallel Initial Load completed in 187s════════════════════════════════════════════════════════════ Tables loaded : 7 (COUNTRIES DEPARTMENTS EMPLOYEES JOBS LOCATIONS REGIONS JOB_HISTORY) FK levels : 2 Parallelism used : 3 concurrent extract slots Slots used total : 7 Init SCN : 6644154 Change Extract : EWEST (RUNNING -- trail ew) Change Dist Path : DPWE (RUNNING -- ew -> dw) Change Replicat : RWEST (RUNNING) Init processes : EI01..EI07 / DP01..DP07 / RI01..RI07 (STOPPED)════════════════════════════════════════════════════════════
Conclusion
This script demonstrates that the GoldenGate 23.26 Microservices REST API is fully capable of automating a sophisticated parallel initial load – table-level pipeline isolation, FK-aware ordering, SCN-consistent snapshots, and precise change replication startup – entirely from shell without the adminclient CLI.
The key architectural insight is the two-phase separation: extracts run as fast as possible (bounded by the slot limit), while deliveries run freely in the background gated only by FK constraints. This means a 100-table schema with 3 extract slots and two FK levels won’t wait for 97 tables to finish extracting before the first delivery starts – delivery of table 1 begins while tables 2 and 3 are still extracting.
The schema being loaded is Oracle’s sample HR schema – 7 tables with two levels of FK dependencies.
The full script is available in my GitHub repository; feel free to use and adapt it as needed.
https://github.com/alexlimahub/PublicCodes/blob/main/initial_load_parallel.sh
Please note that it is provided “as is” without any official support or guarantees. That said, I’m happy to offer guidance on a best-effort basis if you run into questions or need help getting started.

Leave a comment